
【導讀】長短期記憶(LSTM)循環(huán)神經(jīng)網(wǎng)絡可以學習和記憶長段序列的輸入。如果你的問題對于每個輸入都有一個輸出(如時間序列預測和文本翻譯任務),那么 LSTM 可以運行得很好。但 LSTM 在面臨超長輸入序列——單個或少量輸出的情形時就會遇到困難了。這種問題通常被稱為序列標記,或序列分類。
其中的一些例子包括:
包含數(shù)千個單詞的文本內容情緒分類(自然語言處理)。
分類數(shù)千個時間步長的腦電圖數(shù)據(jù)(醫(yī)療領域)。
分類數(shù)千個 DNA 堿基對的編碼/非編碼基因序列(基因信息學)。
當使用循環(huán)神經(jīng)網(wǎng)絡(如 LSTM)時,這些所謂的序列分類任務需要特殊處理。在這篇文章中,你將發(fā)現(xiàn) 6 種處理長序列的方法。
1. 原封不動
原封不動地訓練/輸入,這或許會導致訓練時間大大增長。另外,嘗試在很長的序列里進行反向傳播可能會導致梯度消失,反過來會削弱模型的可靠性。在大型 LSTM 模型中,步長通常會被限制在 250-500 之間。
2. 截斷序列
處理非常長的序列時,最直觀的方式就是截斷它們。這可以通過在開始或結束輸入序列時選擇性地刪除一些時間步來完成。這種方式通過失去部分數(shù)據(jù)的代價來讓序列縮短到可以控制的長度,而風險也顯而易見:部分對于準確預測有利的數(shù)據(jù)可能會在這個過程中丟失。
3. 總結序列
在某些領域中,我們可以嘗試總結輸入序列的內容。例如,在輸入序列為文字的時候,我們可以刪除所有低于指定字頻的文字。我們也可以僅保留整個訓練數(shù)據(jù)集中超過某個指定值的文字??偨Y可以使得系統(tǒng)專注于相關性最高的問題,同時縮短了輸入序列的長度。
4. 隨機取樣
相對更不系統(tǒng)的總結序列方式就是隨機取樣了。我們可以在序列中隨機選擇時間步長并刪除它們,從而將序列縮短至指定長度。我們也可以指定總長的選擇隨機連續(xù)子序列,從而兼顧重疊或非重疊內容。
在缺乏系統(tǒng)縮短序列長度的方式時,這種方法可以奏效。這種方法也可以用于數(shù)據(jù)擴充,創(chuàng)造很多可能不同的輸入序列。當可用的數(shù)據(jù)有限時,這種方法可以提升模型的魯棒性。
5. 時間截斷的反向傳播
除基于整個序列更新模型的方法之外,我們還可以在最后的數(shù)個時間步中估計梯度。這種方法被稱為「時間截斷的反向傳播(TBPTT)」。它可以顯著加速循環(huán)神經(jīng)網(wǎng)絡(如 LSTM)長序列學習的過程。
這將允許所有輸入并執(zhí)行的序列向前傳遞,但僅有最后數(shù)十或數(shù)百時間步會被估計梯度,并用于權重更新。一些最新的 LSTM 應用允許我們指定用于更新的時間步數(shù),分離出一部分輸入序列以供使用。例如:
Theano 中的「truncate_gradient」參數(shù):deeplearning
6. 使用編碼器-解碼器架構
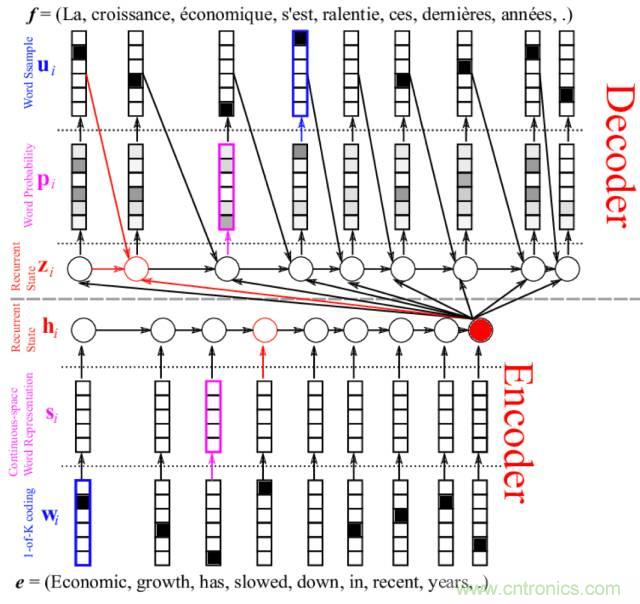
你可以使用自編碼器來讓長序列表示為新長度,然后解碼網(wǎng)絡將編碼表示解釋為所需輸出。這可以是讓無監(jiān)督自編碼器成為序列上的預處理傳遞者,或近期用于神經(jīng)語言翻譯的編碼器-解碼器 LSTM 網(wǎng)絡。
當然,目前機器學習系統(tǒng)從超長序列中學習或許仍然非常困難,但通過復雜的架構和以上一種或幾種方法的結合,我們是可以找到辦法解決這些問題的。
其他瘋狂的想法
這里還有一些未被充分驗證過的想法可供參考。
將輸入序列拆分為多個固定長度的子序列,并構建一種模型,將每個子序列作為單獨的特征(例如并行輸入序列)進行訓練。
雙向 LSTM,其中每個 LSTM 單元對的一部分處理輸入序列的一半,在輸出至層外時組合。這種方法可以將序列分為兩塊或多塊處理。
我們還可以探索序列感知編碼方法、投影法甚至哈希算法來將時間步的數(shù)量減少到指定長度。
推薦閱讀:



